5. A step-by-step introduction to transformer models
Table of contents
- Sequence data and next-token prediction
- Vocabularies, tokenization, and embeddings
- Next token prediction: the task and the loss
- Building attention step by step
- The transformer block
- Practical additions
- Byte pair encoding
- Perplexity
- Conclusion
1. Sequence data and next-token prediction
Last lecture we had data as pairs $(x_i, y_i)$ and learned a model $m(x; w)$ to predict $y$ from $x$. We built linear models (linear regression, logistic regression) and nonlinear models (multi-layer perceptrons, convolutional neural networks). In every case the task was supervised: given an input, produce a target.
Today the setup changes. We have sequence data $(x_1, \ldots, x_T)$ and no label $y$. Examples:
- Raw characters in a sentence.
- Words in English text.
- DNA sequences.
The goal: learn to generate and continue sequences that resemble those in the training data, and that extrapolate beyond them in a consistent way. Given the rise of tools like ChatGPT and Claude, you already know why this matters.
Our running example. Throughout this lecture we train on a Shakespeare dataset (source) consisting of approximately 1.1 million characters. Here is a representative excerpt:
First Citizen:
Before we proceed any further, hear me speak.
All:
Speak, speak.
First Citizen:
You are all resolved rather to die than to famish?
All:
Resolved. resolved.
First Citizen:
First, you know Caius Marcius is chief enemy to the people.
The vocabulary consists of 65 characters: uppercase and lowercase letters, digits, punctuation, spaces, and newlines.
2. Vocabularies, tokenization, and embeddings
2.1 Choosing a vocabulary
Before we can model sequences, we need to encode them on a computer. This requires choosing a vocabulary $V$: a finite set of tokens that the model operates over.
Several choices:
- Characters and digits. Small vocabulary ($\vert V\vert \approx 100$). Every sentence becomes a long sequence of characters. Simple, but the sequences are long and relationships between distant characters can be hard to learn.
- Words. Large vocabulary ($\vert V\vert$ could be $100{,}000+$). Sequences are shorter, but the embedding table grows with $\vert V\vert$.
Smaller vocabularies produce longer sequences that may be harder to optimize, though the optimization problem itself has fewer parameters per token. Larger vocabularies give shorter sequences but inflate the model’s embedding table and the final prediction layer. In practice, modern language models use a middle ground called byte pair encoding (BPE), which we discuss in Section 7. BPE builds a vocabulary of subword units by iteratively merging frequent adjacent pairs. Typical BPE vocabularies have $50{,}000$ to $150{,}000$ tokens. For now we use the character-level vocabulary ($\vert V\vert = 65$) to keep things simple.
We also use two special tokens:
<bos>(beginning of sequence): prepended to every sequence. It gives the model a fixed starting point for generation.<eos>(end of sequence): signals when generation should stop.
2.2 From tokens to vectors: embeddings
Once we have a vocabulary, we need to convert each token into a vector we can do linear algebra on.
For each token $v \in V$, we assign a learnable embedding vector $e_v \in \mathbb{R}^d$. There are $\vert V\vert$ such vectors, one per token, collected into an embedding matrix $E_{\text{vocab}} \in \mathbb{R}^{\vert V\vert \times d}$. These vectors are learned parameters: we initialize them as random Gaussian vectors and let gradient descent shape them during training.
Typical embedding dimensions:
- Small models: $d = 768$
- Large models: $d$ up to $16{,}128$
Both numbers are divisible by $128$. GPU matrix multiplication is fastest when dimensions align to certain powers of $2$. You will see this divisibility pattern throughout deep learning architectures.
Given a sequence $X = (x_1, \ldots, x_T)$ where each $x_t \in V$, the corresponding embedding matrix is
\[E = \begin{bmatrix} e_{x_1}^T \\ e_{x_2}^T \\ \vdots \\ e_{x_T}^T \end{bmatrix} \in \mathbb{R}^{T \times d}.\]Row $t$ is the embedding of the $t$-th token. The first axis is sequence length, consistent with the batch-first convention from last lecture.
In PyTorch, torch.nn.Embedding(vocab_size, d) creates a lookup table that stores $\vert V\vert$ vectors of dimension $d$, initialized from $\mathcal{N}(0, 1)$. Given an integer tensor of token indices, it returns the corresponding rows of this table:
import torch
vocab_size = 65
d = 768
embedding = torch.nn.Embedding(vocab_size, d)
X = torch.tensor([18, 47, 56, 57, 1, 15, 47, 58, 1, 0])
E = embedding(X)
print("X.shape:", X.shape) # torch.Size([10])
print("E.shape:", E.shape) # torch.Size([10, 768])
3. Next token prediction: the task and the loss
3.1 The prediction task
We want to sample sequences that look like those in our training data, and we want to continue partial sequences. A minimal way to achieve both goals: learn to predict the next token in a sequence.
Given a sequence $X = (x_1, \ldots, x_T)$ (with <bos> always prepended by convention), we want a probability distribution over what comes next:
The <bos> token is always present at position $0$, so $p(x_1)$ really means $p(x_1 \mid \langle\text{bos}\rangle)$. We leave this conditioning implicit in all equations that follow.
Once we have this distribution, generation works as follows:
- Sample $x_{T+1} \sim p(\cdot \mid x_1, \ldots, x_T)$.
- Append $x_{T+1}$ to the sequence.
- Repeat: sample $x_{T+2} \sim p(\cdot \mid x_1, \ldots, x_{T+1})$.
- Stop when we reach a maximum number of new tokens or when the model emits
<eos>.
This is autoregressive generation: each new token is sampled conditional on everything before it.
3.2 The model architecture
Our model maps a sequence $X$ to next-token probabilities. This happens in stages:
- Tokenize: convert raw text into a sequence of token indices $X = (x_1, \ldots, x_T)$.
- Embed: look up embeddings to get $E \in \mathbb{R}^{T \times d}$.
- Transform: apply operations to produce $E_{\text{final}} \in \mathbb{R}^{T \times d}$.
- Score: multiply by a learnable matrix $W_{\text{head}} \in \mathbb{R}^{\vert V\vert \times d}$ to get $\text{scores} = E_{\text{final}} W_{\text{head}}^T \in \mathbb{R}^{T \times \vert V\vert}$.
- Normalize: apply softmax row-wise to get probabilities.
Softmax converts a vector of real numbers into a probability distribution. For a vector $z \in \mathbb{R}^n$:
\[\operatorname{softmax}(z)_i = \frac{\exp(z_i)}{\sum_{j=1}^n \exp(z_j)}, \qquad i = 1, \ldots, n.\]Every output is positive (because $\exp$ maps reals to positive reals) and the outputs sum to $1$. Larger entries in $z$ get larger probabilities.
The score matrix has shape $T \times \vert V\vert$. Entry $(t, v)$ measures how likely token $v$ is to follow the first $t$ tokens of $X$. We compute next-token scores for every prefix simultaneously:
\[p(v \mid x_1, \ldots, x_t) = \operatorname{softmax}(E_{\text{final}} W_{\text{head}}^T)_{t,v}.\]Here $W_{\text{head}} \in \mathbb{R}^{\vert V\vert \times d}$ is a learnable weight matrix. Each row of $W_{\text{head}}$ is a template vector for one vocabulary token; the dot product with $e_{\text{final},t}$ produces that token’s score at position $t$.
The central question of this lecture — how do we compute $E_{\text{final}}$ from $E$? — is the subject of Sections 4 and 5. First, we need a training objective.
3.3 The training objective
Our dataset is a collection of sequences $\mathcal{X}$. Assuming each sequence is equally likely and the sequences are independent, a natural objective is maximum likelihood: choose parameters $\theta$ to maximize
\[\prod_{X \in \mathcal{X}} p_\theta(X).\]Here $\theta$ denotes all learnable parameters (embedding vectors, weight matrices, the head matrix $W_{\text{head}}$). For a single sequence $X = (x_1, \ldots, x_T)$, the chain rule of probability gives
\[p_\theta(X) = p_\theta(x_1) \cdot p_\theta(x_2 \mid x_1) \cdots p_\theta(x_T \mid x_1, \ldots, x_{T-1}).\]Recall that <bos> is always implicitly prepended, so $p_\theta(x_1) = p_\theta(x_1 \mid \langle\text{bos}\rangle)$.
Optimizing a product of many small probabilities is numerically fragile: the product can underflow to zero. Taking the negative log converts the product into a sum:
\[\min_\theta \sum_{X \in \mathcal{X}} \sum_{t=1}^{T} -\log p_\theta(x_t \mid x_1, \ldots, x_{t-1}).\]This is the next-token prediction loss. Each term $-\log p_\theta(x_t \mid \cdots)$ penalizes the model for assigning low probability to the token that actually appeared. Because $\log$ is the natural logarithm, the loss is measured in nats (natural units of information); dividing by the number of tokens gives nats per token. A model that assigns uniform probability over $\vert V\vert = 65$ tokens has loss $\log 65 \approx 4.17$ nats/token; any value below this indicates the model has learned something.
In practice the sum over all sequences is too expensive to compute at each step. Instead we estimate it by sampling a random mini-batch of $B$ subsequences of length $T$ from the training data, computing the average loss over the batch, and taking one gradient step. Each subsequence starts at a uniformly random position in the training text, so subsequences overlap and the same character can appear in many different batches across training. In our experiments we use $B = 64$ and $T = 128$. Minimizing this stochastic estimate trains the model to be a good next-token predictor across all positions in all training sequences.
4. Building attention step by step
We now turn to the central question: how do we go from the embedding matrix $E$ to $E_{\text{final}}$?
Experimental setup. To make the comparison concrete, we train each model variant on character-level Shakespeare with $\vert V\vert = 65$, embedding dimension $d = 256$, sequence length $128$, batch size $64$, Adam optimizer with learning rate $3 \times 10^{-4}$, and $10{,}000$ training steps.
4.1 Predict from the last embedding alone
The simplest idea: set $e_{\text{final},t} = e_t$ and predict the next token from the current token’s embedding alone.
\[e_{\text{final},t} = e_t.\]This ignores the rest of the sequence entirely. The next-token prediction depends only on the identity of the current token, not on any context. Given the character “t”, the model outputs the same distribution over the next character regardless of whether “t” appears in “the” or “cat”. It can learn that after “t”, the character “h” is common (because “th” appears often in English), but it assigns the same distribution after every “t” it sees.
This is a bigram model: it learns $p(x_{t+1} \mid x_t)$, the distribution over the next character given only the current character. Figure 4.1 verifies this directly. For four conditioning characters — “t”, “e”, “ “, and “n” — the model’s learned conditional distribution (red) closely matches the data’s bigram frequencies (blue).
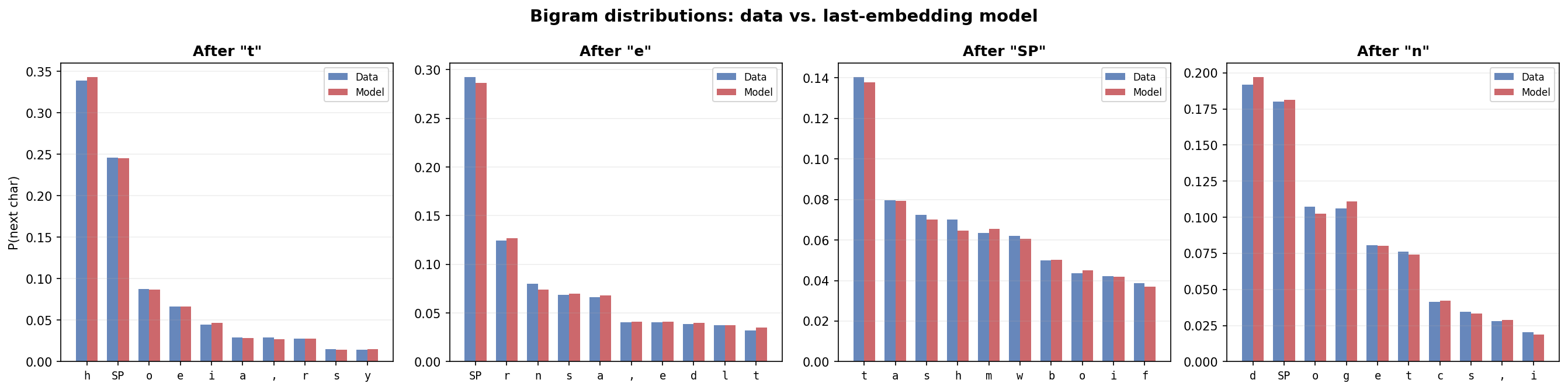
Figure 4.1: Bigram distributions from the training data (blue) versus the trained last-embedding model (red) for four conditioning characters. Each panel shows $p(x_{t+1} \mid x_t)$ for the top 10 most likely next characters. The model closely matches the data’s bigram statistics. (In all figures, “SP” denotes the space character and “\n” denotes newline.)
But the model cannot learn anything beyond bigrams. Consider the contexts “th” and “sh”: both end with “h”, so the model predicts the same distribution after both. In the data, “th” is followed by “e” nearly half the time (for “the”, “them”, “there”, …) while “sh” is followed by “a” and “e” more evenly (“shall”, “she”, …). Figure 4.2 shows this gap: the true trigram distributions (blue, green) differ across contexts, but the model’s prediction (red) is identical because it only sees the final character.
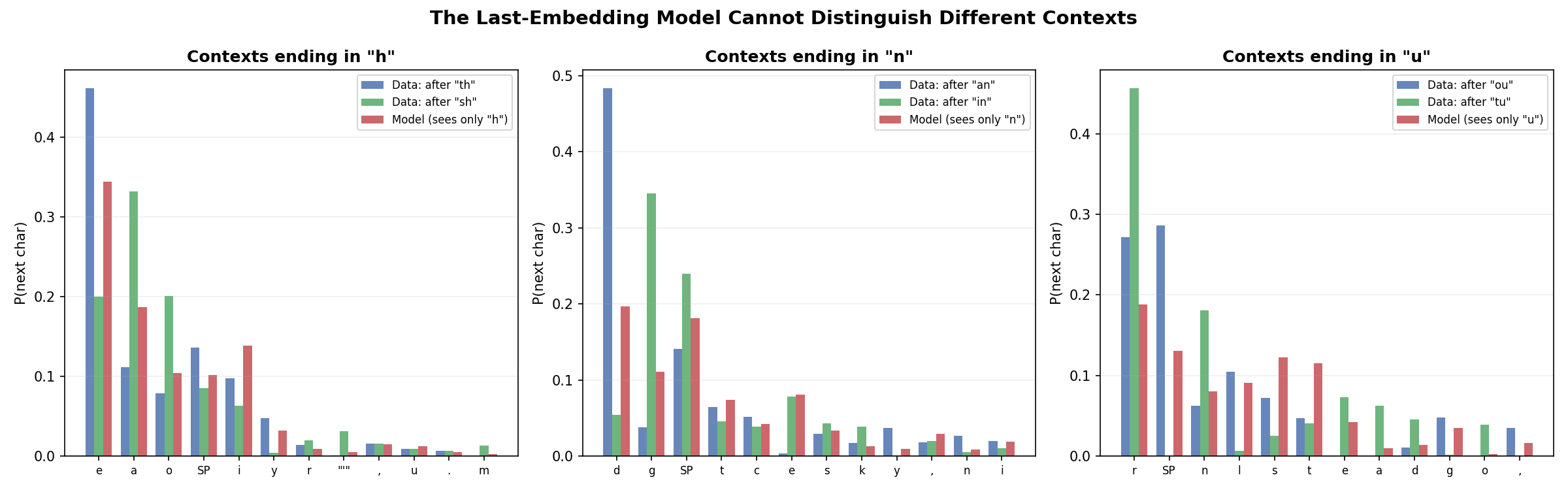
Figure 4.2: The last-embedding model cannot learn trigram structure. Each panel shows two 2-character contexts with the same final character. The data’s trigram distributions (blue, green) differ — $p(x_{t+1} \mid x_{t-1}, x_t)$ depends on $x_{t-1}$ — but the model (red) predicts the same distribution for both because it only conditions on $x_t$.
4.2 Average all embeddings
Combine all positions by averaging:
\[e_{\text{final},t} = \frac{1}{t}\sum_{i=1}^{t} e_i.\](We average over positions $1, \ldots, t$ to respect causality: position $t$ should not see future tokens.) Now every token in the sequence contributes to the prediction. But every token contributes equally. The first character of a sentence has the same influence as the character immediately before the prediction point. In language, recent context usually matters more, and some tokens are far more relevant than others for predicting what comes next.
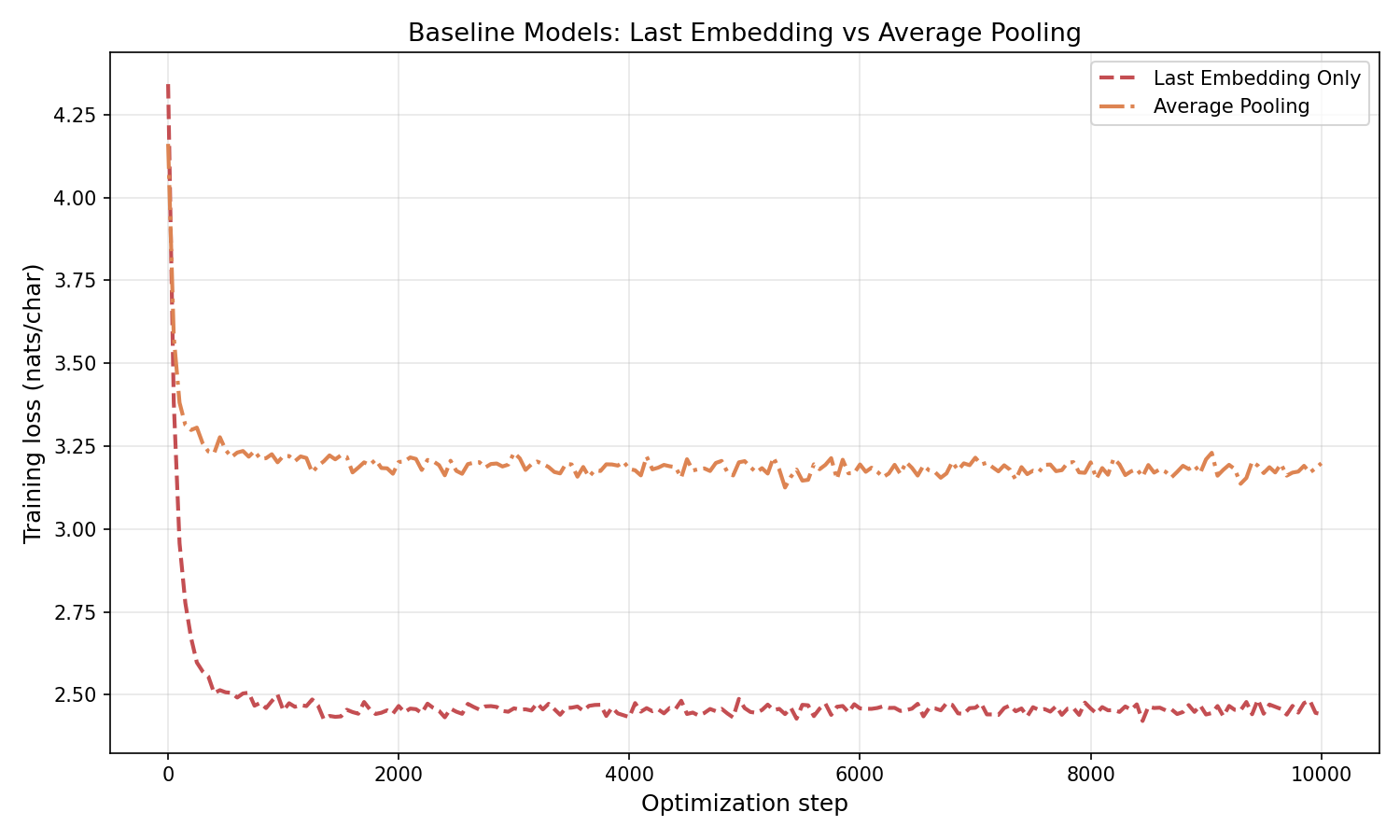
Figure 4.3: Training loss for the two baseline models. Average pooling achieves higher loss than last-embedding-only. Equal weighting dilutes the signal: averaging 128 embeddings pushes the representation toward zero, losing the character-specific information that the last-embedding model exploits. Using context naively is worse than ignoring it.
4.3 Weighted combinations and softmax normalization
We want different tokens to contribute different amounts:
\[e_{\text{final},t} = \sum_{i=1}^{t} a_i \, e_i, \qquad \sum_{i=1}^{t} a_i = 1.\]Where do the weights $a_i$ come from? A natural idea: tokens whose embeddings are more “aligned” with $e_t$ should get more weight. Define $a_i \propto e_i^T e_t$. The dot product $e_i^T e_t$ measures similarity between positions $i$ and $t$. But the normalizing constant $\sum_i e_i^T e_t$ could be zero or negative, making the weights undefined or negative.
Softmax (defined in §3.2) solves this. Apply the exponential function before normalizing:
\[a_i = \frac{\exp(e_i^T e_t)}{\sum_{j=1}^{t} \exp(e_j^T e_t)} = \operatorname{softmax}(E_{1:t} \, e_t)_i.\]Larger dot products produce larger weights, and the weights sum to $1$ by construction.
Scaling by $\sqrt{d}$. If the embeddings are initialized as independent Gaussian vectors with entries from $\mathcal{N}(0,1)$, the dot product $e_i^T e_t$ has standard deviation $\sqrt{d}$. When $d = 256$, dot products can easily reach $\pm 16$. At that magnitude, the exponentials in the softmax create extreme ratios: entries with large positive dot products dominate while entries with large negative dot products effectively vanish. The model starts training in a regime where most of the weight concentrates on a few positions, regardless of the actual content.
Dividing by $\sqrt{d}$ restores unit variance:
\[a_i = \operatorname{softmax}\!\left(\frac{E_{1:t} \, e_t}{\sqrt{d}}\right)_i.\]After this normalization, the cross-terms $e_i^T e_t / \sqrt{d}$ for $i \neq t$ have standard deviation $1$ and are typically in $[-2, 2]$, producing a spread-out distribution that gradient descent can refine.
The self-attention problem. There is a catch. Consider the self-term at position $t$: $e_t^T e_t / \sqrt{d} = \lVert e_t\rVert^2 / \sqrt{d}$. Since $\lVert e_t\rVert^2$ is a sum of $d$ squared standard normals, it concentrates around $d$. So $e_t^T e_t / \sqrt{d} \approx \sqrt{d}$. For $d = 256$, the self-term is $\approx 16$ while the cross-terms are $\mathcal{O}(1)$. The vector $E_{1:t}\, e_t / \sqrt{d}$ has one huge entry (the last one) and the rest are order $1$. The softmax puts almost all weight on position $t$, and we are back to the bigram model.
4.4 Learned transformations: queries, keys, and values
Separate queries and keys. The fix: transform each side with independent matrices. A query matrix $W_Q \in \mathbb{R}^{d \times d}$ transforms the attending position, and a key matrix $W_K \in \mathbb{R}^{d \times d}$ transforms the positions being attended to:
\[a_i = \operatorname{softmax}\!\left(\frac{(W_K e_i)^T (W_Q e_t)}{\sqrt{d}}\right).\]Initialize $W_Q$ and $W_K$ independently with entries from $\mathcal{N}(0, 1/d)$. Then $W_Q e_t$ has entries with variance $\sum_{k=1}^d \operatorname{Var}(W_{Q,jk}) \cdot \operatorname{Var}(e_{t,k}) = d \cdot (1/d) \cdot 1 = 1$, and likewise for $W_K e_i$. The dot product $(W_K e_i)^T (W_Q e_t)$ is a sum of $d$ terms each with variance $1$, so it has standard deviation $\sqrt{d}$. After dividing by $\sqrt{d}$, each entry has standard deviation $1$.
The key point: because $W_Q$ and $W_K$ are independent matrices, $W_Q e_t$ and $W_K e_t$ are independent vectors even when applied to the same input $e_t$. The self-term $(W_K e_t)^T (W_Q e_t) / \sqrt{d}$ has the same distribution as the cross-terms $(W_K e_i)^T (W_Q e_t) / \sqrt{d}$ for $i \neq t$. All entries of $E_{1:t} W_K^T W_Q e_t / \sqrt{d}$ are typically in $[-2, 2]$. The self-attention concentration is gone.
This matters for learning. Consider “The cat sat on the ___”. The most useful tokens for predicting the blank are “sat on”, not the determiner “the” immediately before the blank. With separate $W_Q$ and $W_K$, the model can learn to assign the current position low weight when that is what the data requires.
Value transformation. We have been summing the raw embeddings $e_i$ with learned weights. The embeddings serve double duty: they help determine the weights (through keys) and they are the things being aggregated. A value matrix $W_V \in \mathbb{R}^{d \times d}$ decouples these roles:
\[e_{\text{final},t} = \sum_{i=1}^{t} a_i \, (W_V e_i).\]The value transformation lets the model learn what information to extract from each position, independently of how attention weights are computed.
Putting it all together for position $t$:
\[e_{\text{final},t} = \sum_{i=1}^{t} \operatorname{softmax}\!\left(\frac{(W_K E_{1:t})^T (W_Q e_t)}{\sqrt{d}}\right)_i (W_V e_i).\]Training comparison. Figure 4.4 compares the model variants developed in this section.
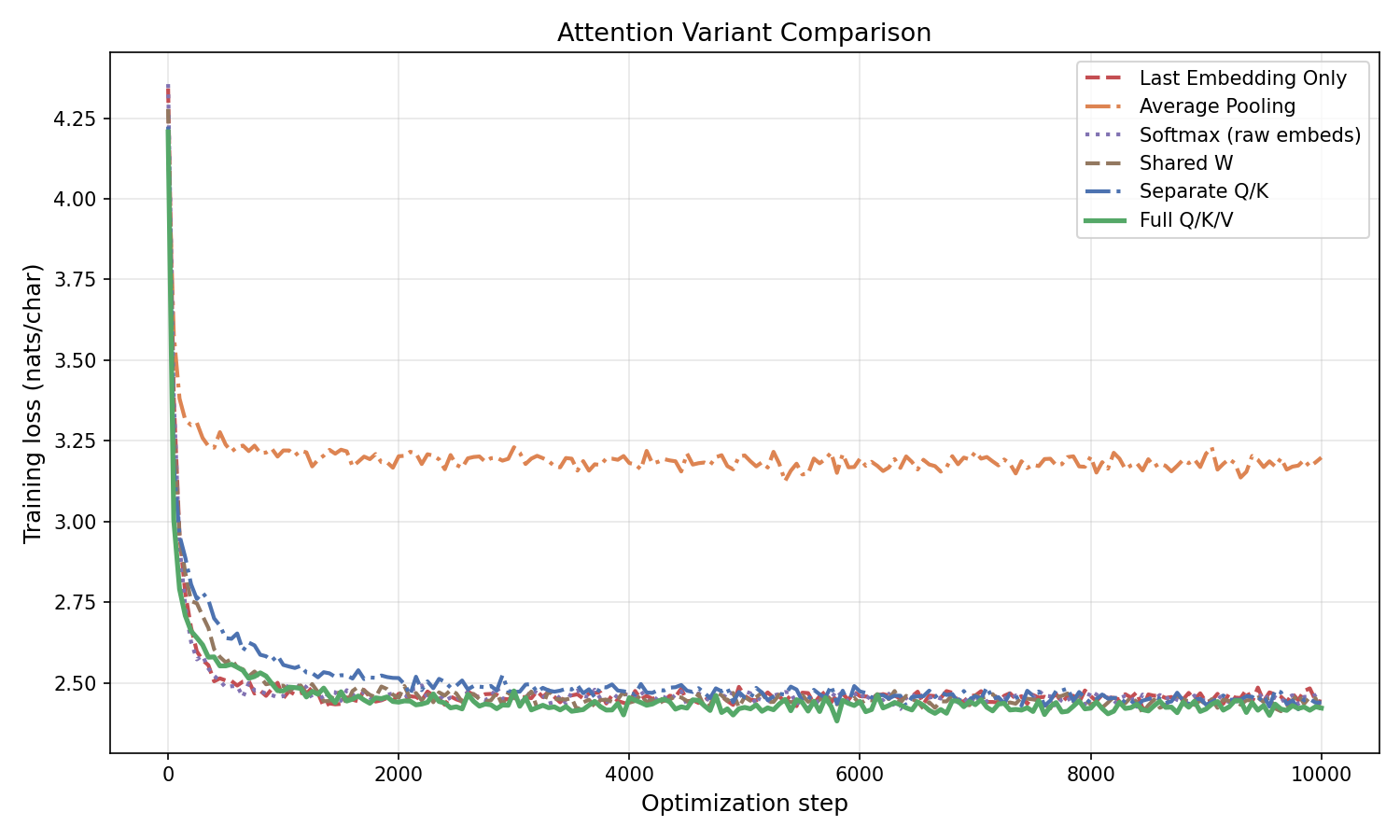
Figure 4.4: Training loss vs. optimization step for attention variants on character-level Shakespeare ($d = 256$, $10{,}000$ steps). Average pooling performs worst due to signal dilution. The attention variants — including a shared-$W$ baseline (same matrix on both sides) — all cluster near the last-embedding model (~2.4 nats/char). Single-layer attention without a feed-forward network or residual connection is not substantially more powerful than a learned bigram model for this task. The big improvements come from stacking full transformer blocks (Section 5).
4.5 The matrix formulation
We can compute the attention output for all positions simultaneously. Define
\[Q = E W_Q^T, \qquad K = E W_K^T, \qquad V = E W_V^T,\]where $Q, K, V \in \mathbb{R}^{T \times d}$. Row $t$ of $Q$ is the query for position $t$; row $i$ of $K$ is the key for position $i$; row $i$ of $V$ is the value for position $i$.
The attention output for the entire sequence is
\[\operatorname{Attn}(E) = \operatorname{softmax}\!\left(\frac{QK^T + M}{\sqrt{d}}\right) V,\]where softmax is applied row-wise, and $M \in \mathbb{R}^{T \times T}$ is a causal mask:
\[M_{t,i} = \begin{cases} 0 & \text{if } i \le t, \\ -\infty & \text{if } i > t. \end{cases}\]The $-\infty$ entries cause $\exp(-\infty) = 0$ in the softmax, so position $t$ cannot attend to any future position $i > t$. Without the mask, position $t$ could look at the actual next token when predicting it, and autoregressive generation (where we produce tokens one at a time, left to right) would not make sense. The causal mask also provides some positional information: position $t$ attends to a different set of positions than position $t’$, though within the attended set $\lbrace 1, \ldots, t\rbrace$ the model cannot distinguish position order without additional encoding (see §6.2).
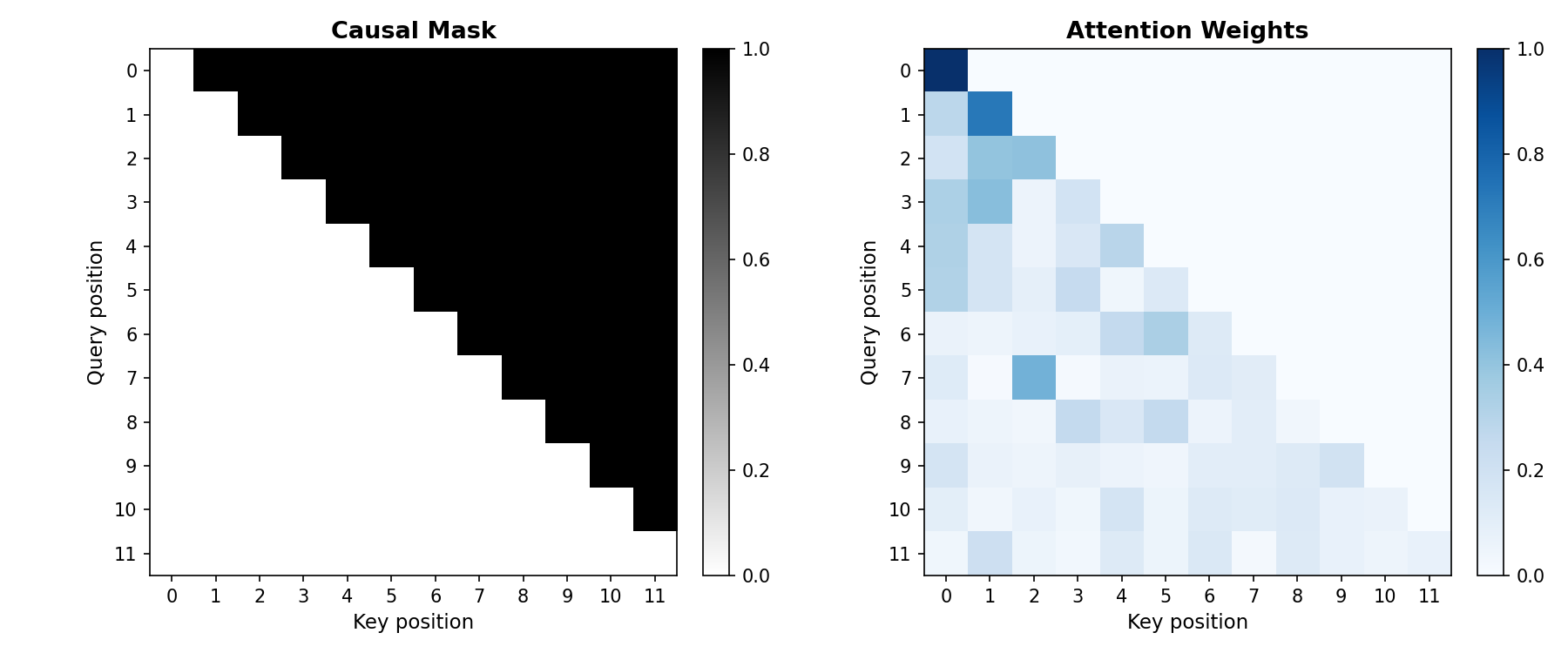
Figure 4.5: Left: the causal mask for a 12-token sequence. White entries are $0$ (attend); dark entries are $-\infty$ (block). Right: attention weights after softmax. Each row sums to $1$ and only attends to earlier (or equal) positions.
The matrix $\operatorname{Attn}(E)$ is $T \times d$. Row $t$ is a weighted combination of the value vectors $\lbrace v_1, \ldots, v_t\rbrace$, where the weights are determined by how well query $t$ matches keys $1, \ldots, t$. This mechanism was introduced in “Attention Is All You Need” (Vaswani et al., 2017), the paper that established the transformer architecture.
import torch
import torch.nn.functional as F
torch.manual_seed(0)
T, d = 10, 768
E = torch.randn(T, d)
W_Q = torch.randn(d, d) * (d ** -0.5)
W_K = torch.randn(d, d) * (d ** -0.5)
W_V = torch.randn(d, d) * (d ** -0.5)
Q = E @ W_Q.T # (T, d)
K = E @ W_K.T # (T, d)
V = E @ W_V.T # (T, d)
scores = (Q @ K.T) / (d ** 0.5) # (T, T)
mask = torch.triu(torch.full((T, T), float('-inf')), diagonal=1)
scores = scores + mask
attn_weights = F.softmax(scores, dim=-1) # (T, T)
attn_output = attn_weights @ V # (T, d)
print("Q.shape:", Q.shape) # torch.Size([10, 768])
print("scores.shape:", scores.shape) # torch.Size([10, 10])
print("attn_weights.shape:", attn_weights.shape) # torch.Size([10, 10])
print("attn_output.shape:", attn_output.shape) # torch.Size([10, 768])
print("attn_weights[0]:", attn_weights[0].tolist()[:3])
5. The transformer block
Attention gives us a way to compute a context-aware representation $\operatorname{Attn}(E)$. We could stop here and feed this directly into the prediction head. But recall the idea from last lecture: deep learning transforms raw data into a form that is more useful for the final layer. Attention is one transformation. We can compose it with others to make the representation richer.
5.1 Residual connections
Instead of replacing $E$ with $\operatorname{Attn}(E)$, add them:
\[E' = \operatorname{Attn}(E) + E.\]This is a residual connection. The model can learn to use the attention output as a correction to the original embeddings rather than replacing them entirely.
Why does this help? You will find all sorts of explanations online (“it keeps the gradient flowing,” etc.). Most of them are hand-wavy. My best guess is that residual connections improve the conditioning of the optimization problem. Conditioning is not something we have covered in this course, and I have not verified this claim carefully, but that is where I would start if pressed for an explanation.
5.2 The feed-forward network
Attention computes a weighted combination of value vectors. The weights $a_i$ are nonlinear functions of the input (they pass through softmax), and the values $W_V e_i$ are linear transforms of the embeddings. But there is no element-wise nonlinearity applied to each position’s representation after the weighted sum. A feed-forward network (MLP) adds this:
\[\operatorname{MLP}(E') = \operatorname{ReLU}(E' W_1^T)\, W_2^T,\]where $W_1 \in \mathbb{R}^{4d \times d}$ and $W_2 \in \mathbb{R}^{d \times 4d}$. The computation maps $d \to 4d \to d$: expand to a wider representation, apply ReLU, then project back. The factor of $4$ is a convention from the original transformer paper.
We again add a residual connection:
\[E'' = \operatorname{MLP}(E') + E'.\]5.3 A single transformer block
Composing these two pieces, a single transformer block is
\[\text{Block}(E) = (\operatorname{MLP} + I) \circ (\operatorname{Attn} + I)(E),\]where $I$ denotes the identity (the residual connections). First we mix information across positions via attention, then we transform within each position via the MLP. Both steps preserve the residual.
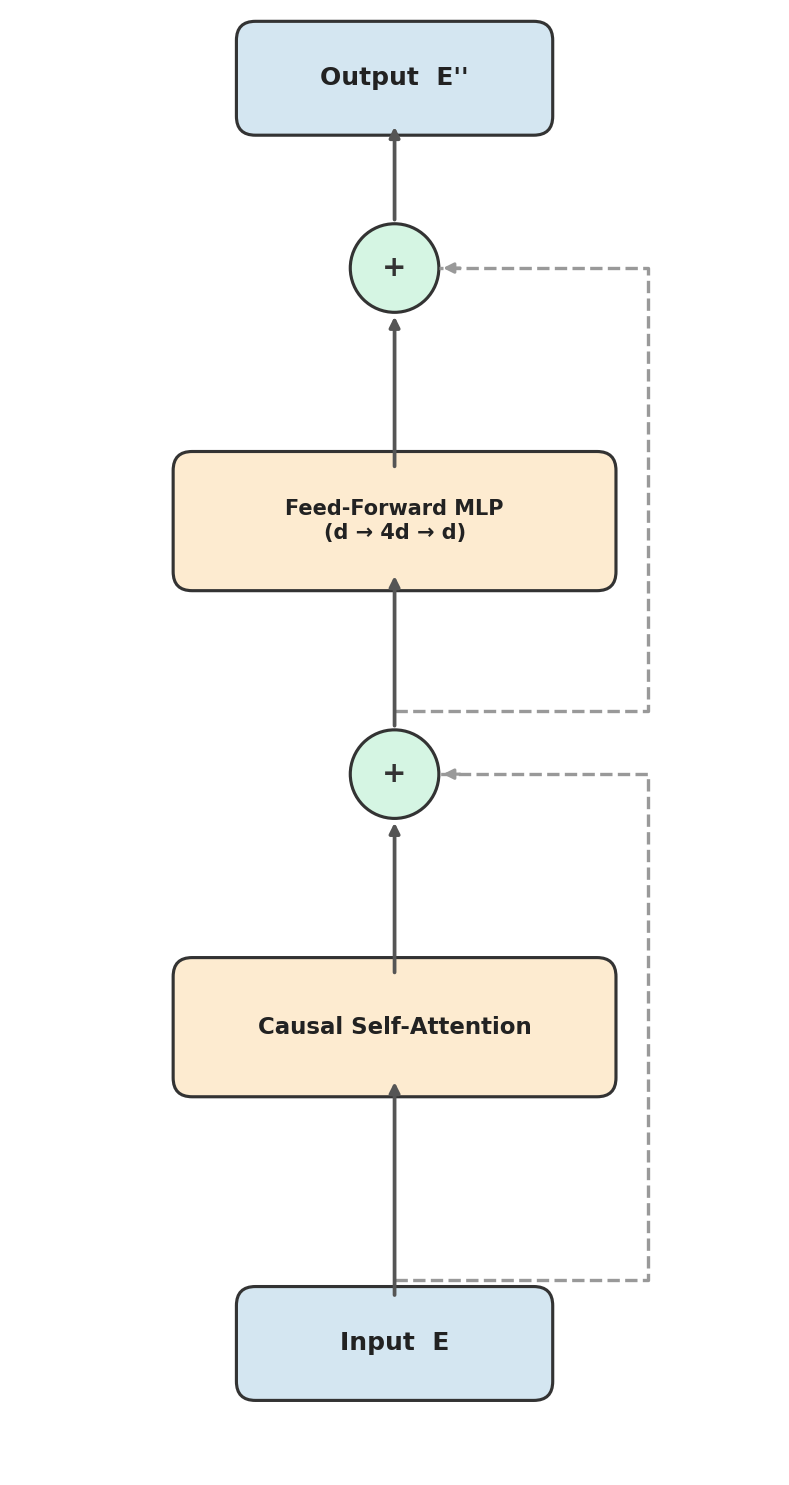
Figure 5.1: A single transformer block. The input $E$ passes through causal self-attention (with a residual connection), then through a feed-forward MLP (with another residual connection), producing $E’’$ of the same shape.
5.4 Stacking blocks: the full transformer
A single transformer block has limited expressive power. To build a richer model, we stack $L$ blocks. Starting with the embedding $E_0 = E$, for $\ell = 1, \ldots, L$:
\[E_\ell = (\operatorname{MLP}_\ell + I) \circ (\operatorname{Attn}_\ell + I)(E_{\ell-1}).\]Define $E_{\text{final}} = E_L$. Each block has its own learnable parameters: three weight matrices $W_{Q,\ell}, W_{K,\ell}, W_{V,\ell} \in \mathbb{R}^{d \times d}$ for attention, and two weight matrices $W_{1,\ell} \in \mathbb{R}^{4d \times d}$, $W_{2,\ell} \in \mathbb{R}^{d \times 4d}$ for the MLP.
Parameter count. Each attention layer has $3d^2$ parameters (from $W_Q, W_K, W_V$). Each MLP has $4d^2 + 4d^2 = 8d^2$ parameters (from $W_1$ and $W_2$). So each block contributes $11d^2$, and $L$ blocks contribute $11Ld^2$. Adding the embedding table ($\vert V\vert d$) and the prediction head $W_{\text{head}}$ ($\vert V\vert d$), the total is
\[\text{params} = 2\vert V\vert d + 11Ld^2.\]For our experiments with $\vert V\vert = 65$, $d = 256$, $L = 4$: $2 \cdot 65 \cdot 256 + 11 \cdot 4 \cdot 256^2 = 33{,}280 + 2{,}883{,}584 = 2{,}916{,}864$ parameters. The per-block term $11Ld^2$ dominates the embedding term $2\vert V\vert d$ once $Ld \gg \vert V\vert$. With character-level tokens ($\vert V\vert = 65$), this happens immediately. With BPE ($\vert V\vert \approx 100{,}000$) and $d \approx 10{,}000$, the crossover is around $L \approx 10$ layers.
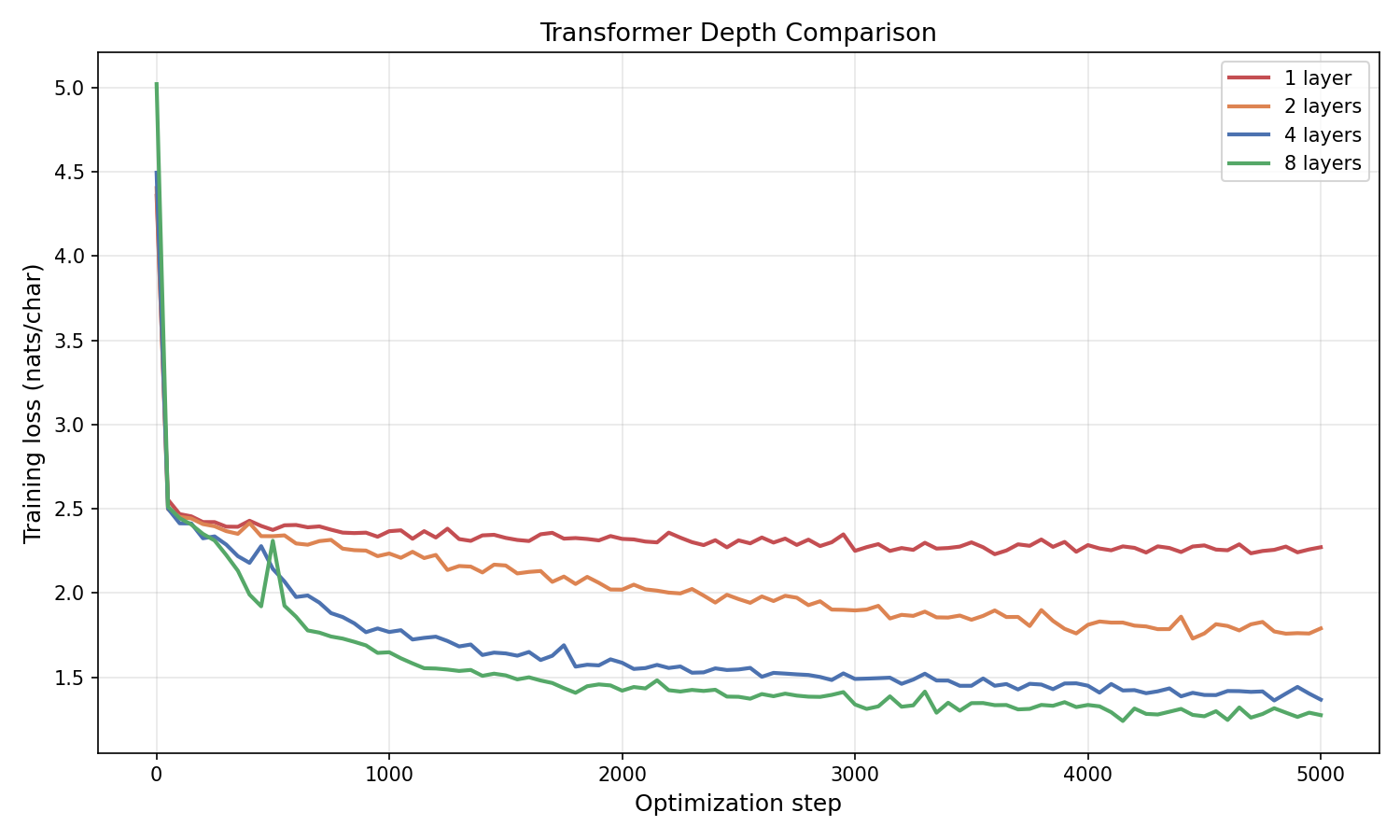
Figure 5.2: Training loss vs. optimization step for transformers with 1, 2, 4, and 8 layers on character-level Shakespeare ($d = 256$, $10{,}000$ steps). Deeper models achieve lower training loss. The gap between 1 and 2 layers is substantial; returns diminish as depth increases further. Compare to Figure 4.4: adding the full transformer block (attention + residual + MLP) produces far larger gains than any of the attention-only variants.
5.4.1 Stacking attention-only blocks
How much of the improvement in Figure 5.2 comes from the MLP? We can isolate the contribution by stacking attention-only blocks — each block computes $E \leftarrow E + \operatorname{Attn}(E)$, with no feed-forward network.
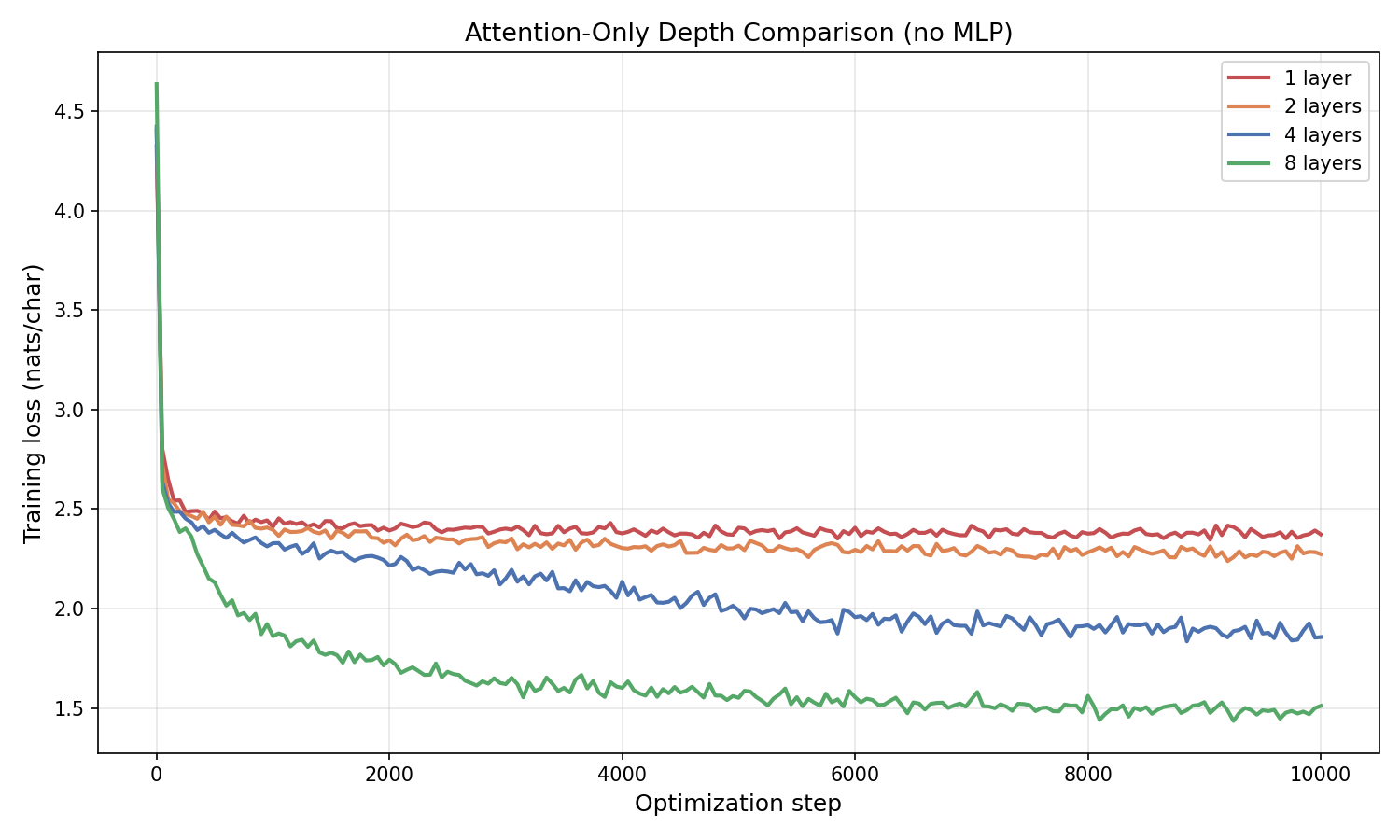
Figure 5.2.1: Training loss for attention-only blocks (no MLP) at depths 1, 2, 4, and 8 ($d = 256$, $10{,}000$ steps). Stacking attention layers with residual connections does improve performance: the 8-layer attention-only model reaches $\approx 1.50$ nats/char. But compare to the full transformer block in Figure 5.2: the 4-layer full transformer ($\approx 1.25$) beats the 8-layer attention-only model, and the 2-layer full transformer ($\approx 1.63$) beats the 4-layer attention-only ($\approx 1.88$). The MLP provides substantial additional capacity at every depth.
5.5 PyTorch implementation
Here is a complete, runnable transformer built from the components above.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CausalSelfAttention(nn.Module):
def __init__(self, d):
super().__init__()
self.W_Q = nn.Linear(d, d, bias=False)
self.W_K = nn.Linear(d, d, bias=False)
self.W_V = nn.Linear(d, d, bias=False)
self.scale = d ** 0.5
def forward(self, E):
T = E.shape[-2]
Q, K, V = self.W_Q(E), self.W_K(E), self.W_V(E)
scores = (Q @ K.transpose(-2, -1)) / self.scale
mask = torch.triu(torch.full((T, T), float('-inf'), device=E.device), diagonal=1)
attn = F.softmax(scores + mask, dim=-1)
return attn @ V
class TransformerBlock(nn.Module):
def __init__(self, d, d_ff=None):
super().__init__()
if d_ff is None:
d_ff = 4 * d
self.attn = CausalSelfAttention(d)
self.mlp = nn.Sequential(
nn.Linear(d, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d),
)
def forward(self, E):
E = E + self.attn(E)
E = E + self.mlp(E)
return E
class SimpleTransformer(nn.Module):
def __init__(self, vocab_size, d, num_layers):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d)
self.blocks = nn.ModuleList([TransformerBlock(d) for _ in range(num_layers)])
self.head = nn.Linear(d, vocab_size, bias=False)
def forward(self, x):
E = self.embedding(x)
for block in self.blocks:
E = block(E)
return self.head(E)
torch.manual_seed(0)
vocab_size, d, num_layers = 65, 768, 4
model = SimpleTransformer(vocab_size, d, num_layers)
x = torch.randint(0, vocab_size, (1, 32))
logits = model(x)
print("input shape:", x.shape) # torch.Size([1, 32])
print("output shape:", logits.shape) # torch.Size([1, 32, 65])
print("num parameters:", sum(p.numel() for p in model.parameters()))
for name, p in model.named_parameters():
print(f" {name}: {tuple(p.shape)}")
5.6 Generating text
Here are 300-character samples from four of our trained models, generated autoregressively at temperature $0.8$.
(a) Last Embedding Only. A bigram model: each character depends on the previous one, producing common pairs like “th” and “he”, but no coherent words or longer structure:
Wh shinal dawome usio ith by thy ghe t trongat prerend thin e ime mmas y I r d: HAng, bo th’ewe Buraithe ale e ant stafr onour nor ghere thisuls acoupren’stofo hed winoothans Pr I grou ay che lombood, blles thatig. TEYouthe l telve that. There ild I’d e: RLerirondeisthe pr s t s, thellknge worir, f
(b) Average Pooling. The signal is diluted by equal weighting; the output is less coherent than (a):
ICES:ehan t sf woihaldl,’ am ladatfr fti,thypwioeoe yontld e sel,ooe s : crhht n teeou e u eetreWwsisrb r e yltdomshl he moelr rndirad le peh hhteenseba yt bfouiu.hmttcsasece rnneeb siaebhh em.Knete;twott ehoesr u sw tr tsoT,’‘esaaoult ncdt amholyft A er se: ohs ac t ra o wst a b I o
(c) Single-Layer Q/K/V Attention. Some word-like patterns emerge, but no real English words:
Be nous f athecalind wn t de thatho acicrmathiliny and be; cindyosthanf bun, ound isiber ithin thalpes s ibo wourr ofouloutanoty ngtrarel: torshimare’t an he o t m’seme he foditig he oupo ferstheeathourer outhe, edsben athan ane cost lebritokseaththeror at pet teclly le hay sean tha wanthesinthellt
(d) 4-Layer Attention-Only (no MLP). Formatting and common word fragments appear, but many nonsense words remain (“noblod,” “ereat,” “brenath”). Compare to (e) below — the MLP makes a visible difference:
My thou for dunay and are the a our of noblod te the ereat hes er magre, Are chand thall king, they but the in’u ce sie the men.
First Lon low of lie her and how not brenath if likest Thy cherear, but men court thinke anown; Than like ward Therr: my and momean a ques Thes to souch, by the my and br
(e) 4-Layer Transformer. Recognizable formatting with line breaks, character names, and English words:
That by it be encountere of his brother.
MARCIUS: Well, and you come? o, sir, I think, so gentlemen.
MARIANA: I have done enoumenance.
MARCIUS: One how the househer to my lord.
SICINIUS: Your honour’s warrs dead: When they law often ears thou enear the dates them no will of meen I from your high
5.7 Temperature
The samples above were generated at temperature $\tau = 0.8$. Temperature is a single scalar that controls the sharpness of the sampling distribution. At each step, the model computes scores $s = (E_{\text{final}} W_{\text{head}}^T)_{t,:} \in \mathbb{R}^{\vert V\vert}$ for the next token. We divide by $\tau$ before applying softmax:
\[p(x_{t+1} = v \mid x_1, \ldots, x_t) = \frac{\exp(s_v / \tau)}{\sum_{v'} \exp(s_{v'} / \tau)}.\]- $\tau = 1$: the raw learned distribution, unchanged.
- $\tau < 1$: the distribution sharpens. High-probability tokens become even more likely. As $\tau \to 0$, sampling converges to always picking the single most likely token (greedy decoding).
- $\tau > 1$: the distribution flattens. Low-probability tokens get a larger share. As $\tau \to \infty$, the distribution approaches uniform over the vocabulary.
Figure 5.3 shows this concretely. We feed the context KING RICHARD II:\n into the 4-layer transformer and plot the resulting probability over the 15 highest-scoring tokens at five temperatures.
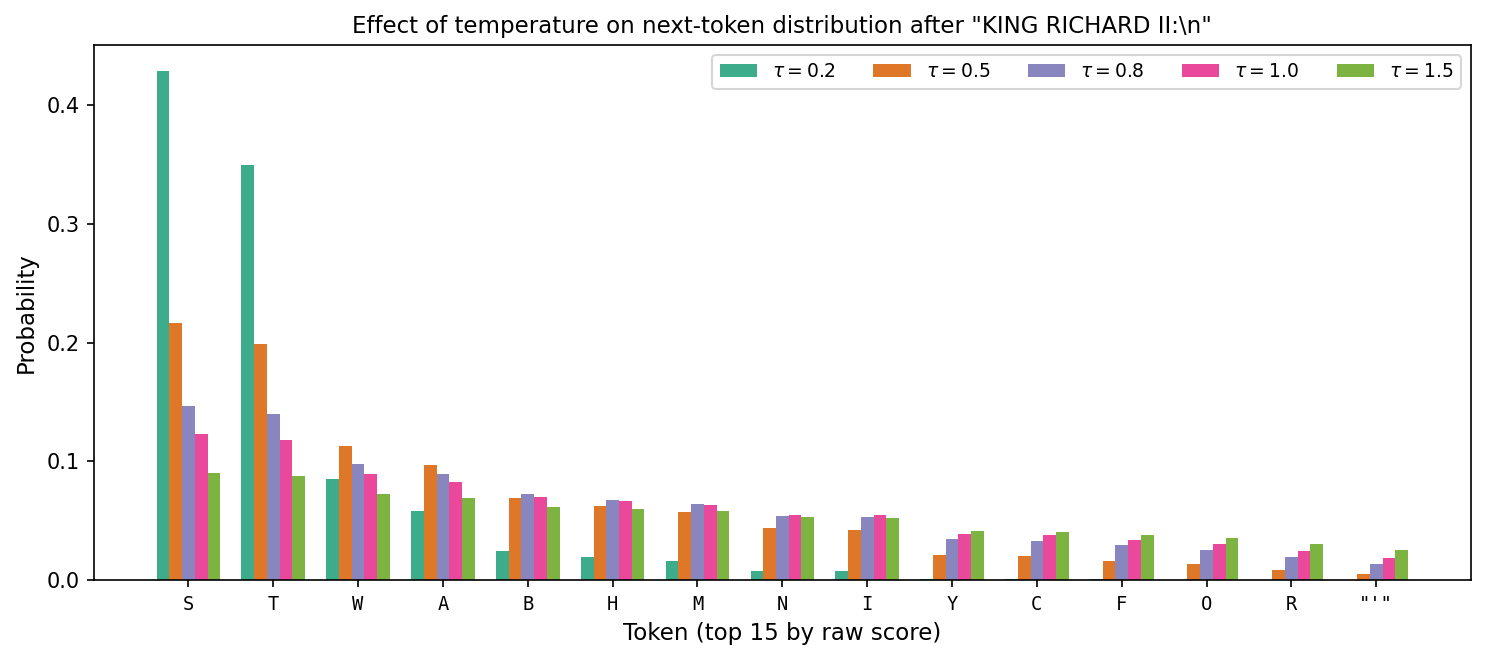
Figure 5.3: Next-token probabilities after the context “KING RICHARD II:\n” at five temperatures. At $\tau = 0.2$, nearly all mass concentrates on “S” and “T” (the most common first letters of speech lines). At $\tau = 1.5$, the distribution is nearly flat and rare continuations become almost as likely as common ones.
In code, this is one line: divide the scores by $\tau$ before softmax.
scores = model(context)[0, -1, :] # shape (|V|,) — next-token scores
scores = scores / temperature # scale
probs = torch.softmax(scores, dim=-1)
next_token = torch.multinomial(probs, 1)
Here are 200-character samples from the same 4-layer transformer at five temperatures:
$\tau = 0.2$ (near-greedy: repetitive, safe)
LUCIO: Well, well, my lord, I will be not a subject of the death of the dead that the rest, And so the commoner of my son and the state of my heart.
$\tau = 0.5$ (moderately sharp: coherent, limited variety)
KING RICHARD II: Sweet when I was all not so farewell, And see him to come and by that strength to be the commoney.
ANGELO: I have all the flatteriest of her no more.
$\tau = 0.8$ (default: readable with some creativity)
KING RICHARD II: The duke: sure, thou noble courteor.
DUKE OF AUMERLE: Provost, and let us not so, To please upon mine earth. Come, like thy house: Mercy harm of my prevail is like the contract,
$\tau = 1.0$ (raw distribution: occasional misspellings, more variety)
KING LEWIS XI: No, monstrous and over nobled fe thy effer he deputy; To dreamts we maid the north, Must be it uncertain fame ne’er in his chalf cold offend and gone.
$\tau = 1.5$ (flattened: frequent nonsense, rare tokens appear)
Likely, for this natural childrent to anquen’d. KING EDWARD IV: No; and I, Rotak, to; ‘God, no neek utting in’u cersit that Ine’d no honour flescily of
The pattern: low temperature produces safe, repetitive text; high temperature introduces variety at the cost of coherence. Most deployed language models sample at $\tau$ between $0.7$ and $1.0$.
6. Practical additions
The architecture in Section 5 captures the core structure of a transformer. Three additional components are standard in practice.
6.1 Output projection
After computing the attention output $\operatorname{Attn}(E)$, apply a learned matrix $W_O \in \mathbb{R}^{d \times d}$:
\[\operatorname{Attn}_{\text{proj}}(E) = \operatorname{Attn}(E)\, W_O^T.\]This gives the model an additional degree of freedom to transform the attention output before adding the residual.
6.2 Positional encodings
The causal mask restricts which positions each token can attend to, but within the attended set $\lbrace 1, \ldots, t\rbrace$, the attention computation treats tokens as a set: permuting positions $1$ through $t$ (while keeping the same embeddings) does not change the weighted sum. The model has no way to know which token came first and which came fifth.
To give the model explicit position information, we add a positional encoding $P \in \mathbb{R}^{T \times d}$ to the embeddings:
\[E_0 = E + P.\]The original transformer used a deterministic sinusoidal encoding:
\[P_{t, 2k} = \sin\!\left(\frac{t}{10000^{2k/d}}\right), \qquad P_{t, 2k+1} = \cos\!\left(\frac{t}{10000^{2k/d}}\right).\]Different frequencies along different dimensions of $d$ encode position at multiple scales. In code, adding positional encoding is a one-line change to the forward pass: E = self.embedding(x) + self.pe[:T], where self.pe is a precomputed buffer.
Many modern architectures use learned positional encodings or relative position schemes. A widely used variant is Rotary Position Embedding (RoPE) (Su et al., 2021), which encodes relative positions through rotations in the query-key dot product.
Training comparison. Figure 6.1 compares a 4-layer transformer with and without sinusoidal positional encoding.
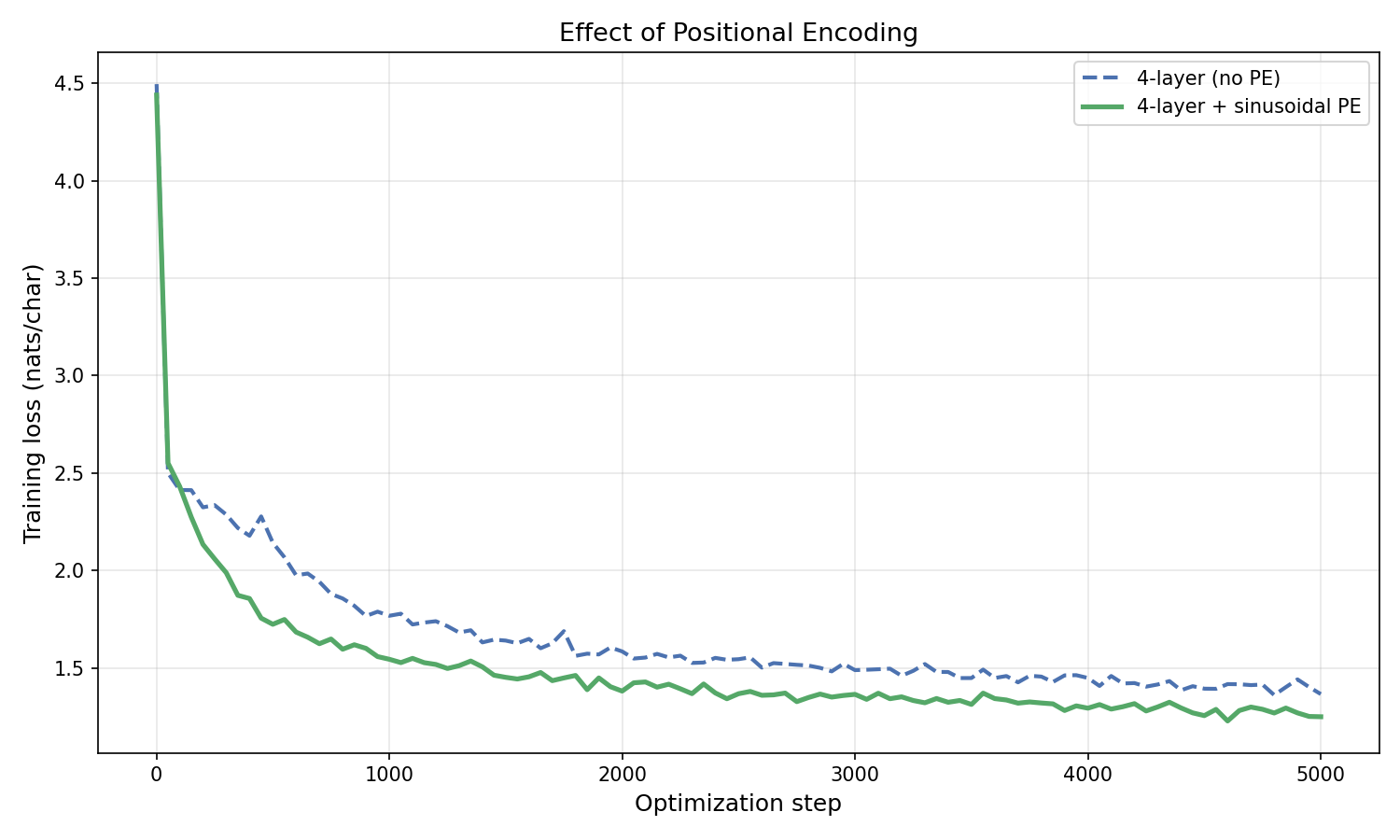
Figure 6.1: Training loss for a 4-layer transformer with and without sinusoidal positional encoding ($d = 256$, $10{,}000$ steps). Positional encoding provides a consistent advantage, particularly later in training when the model has learned enough structure to exploit position information.
Here is a sample from the 4-layer transformer with positional encoding (compare to sample (e) in §5.6):
Shall uncle you sure That he has merry to me a power: if your agger and as she And prive as ‘twere myself; for if the strength of a soldiers.
Third Servingman: Shall this have touch mind incontent him! I say, if you discharge for such lord’s sweetest Make mine of me, but then in his hireit: Whilst
6.3 Multiple attention heads
A single attention layer computes one set of weights $a_{t,i}$ and one weighted combination. Different aspects of language may require attending to different things simultaneously: syntax might depend on nearby tokens while semantic reference might depend on distant ones.
Multi-head attention splits the embedding dimension $d$ into $h$ heads, each of dimension $d_h = d/h$. Each head has its own $W_Q^{(j)}, W_K^{(j)}, W_V^{(j)}$ matrices (now $d \times d_h$ instead of $d \times d$), computes attention independently, and the $h$ outputs are concatenated:
\[\operatorname{MultiHead}(E) = \operatorname{Concat}(\text{head}_1, \ldots, \text{head}_h)\, W_O^T,\]where each $\text{head}_j = \operatorname{Attn}_j(E) \in \mathbb{R}^{T \times d_h}$. The concatenation produces a $T \times d$ matrix, and the output projection $W_O \in \mathbb{R}^{d \times d}$ mixes the heads. The total parameter count is similar to single-head attention, but different heads can specialize in different patterns.
7. Byte pair encoding
So far we have used a character-level vocabulary with $\vert V\vert = 65$ tokens. Character-level tokenization is simple but produces long sequences: a 1000-word passage might be 5000+ characters. Longer sequences mean more computation per training step (the attention matrix is $T \times T$) and more difficulty learning long-range dependencies.
Byte pair encoding (BPE) starts with individual characters and iteratively merges the most frequent adjacent pair into a new token. After enough merges, common words like “the” become single tokens, while rare words are split into subword pieces. The GPT-2 tokenizer uses BPE with a vocabulary of $50{,}257$ tokens. For an interactive walkthrough of the merging process, see this BPE demo.
Here is how the same Shakespeare text looks under both tokenizers:
import tiktoken
enc = tiktoken.get_encoding("gpt2")
text = "First Citizen:\nBefore we proceed any further, hear me speak.\n"
char_tokens = list(text)
bpe_tokens = [enc.decode([t]) for t in enc.encode(text)]
print(f"Characters: {len(char_tokens)} tokens")
# Characters: 62 tokens
print(f"BPE: {len(bpe_tokens)} tokens")
# BPE: 16 tokens
print(f"Compression: {len(char_tokens)/len(bpe_tokens):.1f}x")
# Compression: 3.9x
print(f"BPE tokens: {bpe_tokens}")
# BPE tokens: ['First', ' Citizen', ':\n', 'Before', ' we', ' proceed', ' any', ' further', ',', ' hear', ' me', ' speak', '.', '\n']
The tradeoffs:
| Character-level | BPE | |
|---|---|---|
| Vocab size | $65$ | $50{,}257$ |
| Sequence length (1000 words) | $\sim 5000$ | $\sim 1300$ |
| Embedding table params ($d = 256$) | $16{,}640$ | $12{,}865{,}792$ |
| Attention cost per step | $T^2 = 25\text{M}$ | $T^2 = 1.7\text{M}$ |
BPE sequences are roughly $4\times$ shorter, which quadratically reduces attention cost. The $T^2$ factor comes from the attention score matrix $QK^T \in \mathbb{R}^{T \times T}$: every position’s query is compared to every other position’s key, so the computation scales as $T^2$. Cutting $T$ by $4\times$ reduces this cost by $16\times$. But the embedding table is $800\times$ larger. For large models where $d$ is much bigger than $\vert V\vert$, this overhead is negligible. For our small $d = 256$ models, the BPE embedding table dominates the parameter count.
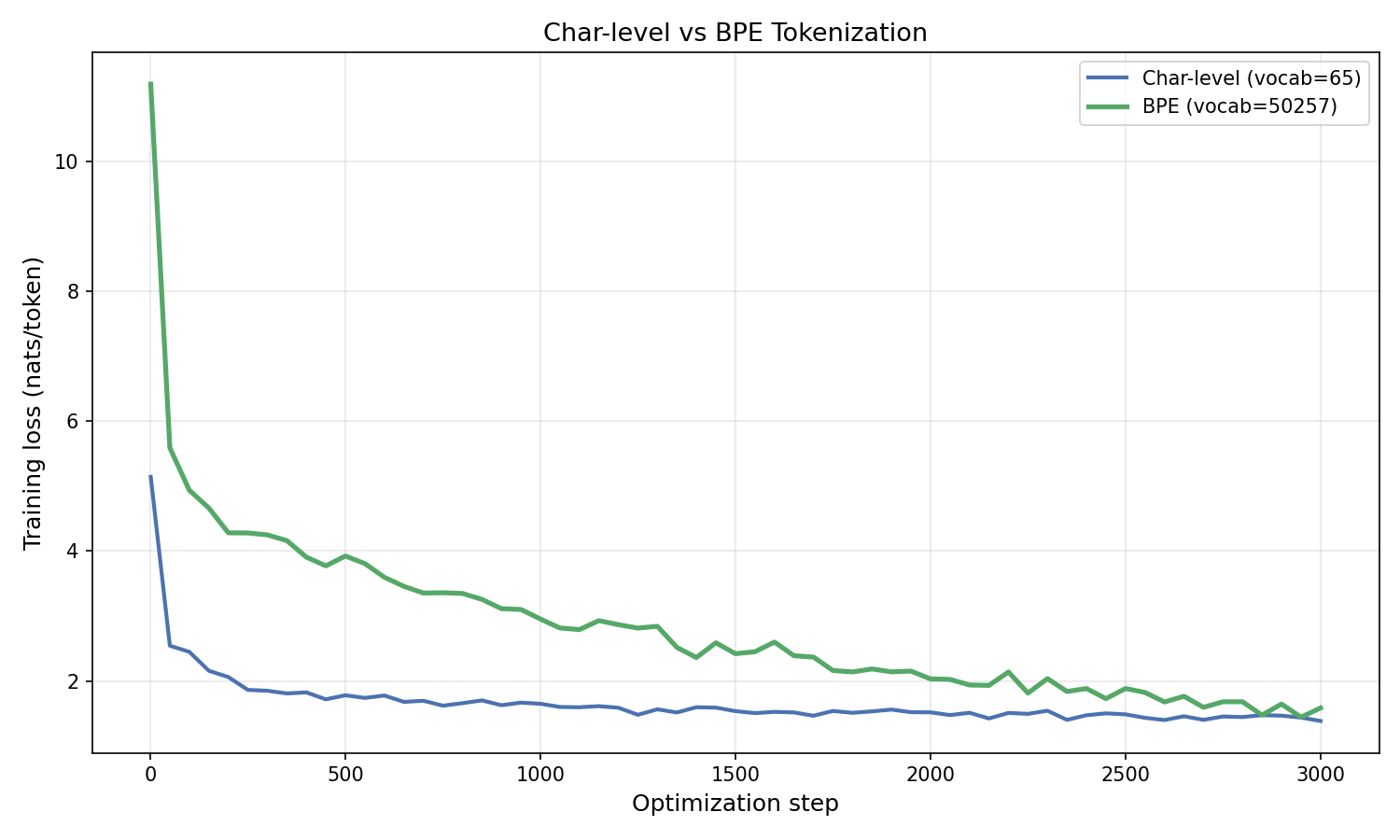
Figure 7.1: Training loss for 4-layer transformers with sinusoidal positional encoding ($d = 256$, $3{,}000$ steps) trained on character-level vs. BPE tokenization. The losses are not directly comparable because the models predict different-sized tokens. The BPE model has $28.6\text{M}$ parameters (vs. $2.9\text{M}$ for char-level) due to its $50{,}257$-token embedding table; with only $304{,}000$ training tokens, the BPE model is significantly undertrained relative to its capacity.
Here are samples from both models (temperature $0.8$):
Char-level (vocab = 65):
Let me knocked with us, some call him to the sorrow. VOLUMNIA: Before it in Christians are Forbituous a sweet, Be in pitcher with all one exileness, and you are tale to the earth of a blow be to the dark. I save thy king my clouck, Deserve here and yet him hence lives their tred, Or call’d of that
BPE (vocab = 50,257):
AUTOLYCUS: Ay, with mere him, Bohemia You have respected appear: and I have this: offer’d Norfolk, The garter for the getting a tinker’s truth! You that’s the chosen: whom should they are ignorant, Though calved I’ the porch o’ the Capitol– this admits Aed with me; ‘tis a
The BPE model produces more coherent words because each token is already a subword unit, but both models are trained for the same number of steps on a small-scale architecture.
8. Perplexity
Throughout this lecture we reported training loss in nats per token. The standard metric in language modeling is perplexity. To define it, start from the quantity we already have.
Our training loss for a sequence $X = (x_1, \ldots, x_T)$ is
\[\mathcal{L} = \frac{1}{T}\sum_{t=1}^{T} -\log p_\theta(x_t \mid x_1, \ldots, x_{t-1}).\]This is the average negative log-likelihood per token. When we train on multiple sequences, we average over all tokens across all of them.
Recall from Section 3.3 that the likelihood of the data is the product $\prod_{t=1}^{T} p_\theta(x_t \mid x_1, \ldots, x_{t-1})$. The inverse of this product is
\[\frac{1}{\prod_{t=1}^{T} p_\theta(x_t \mid x_1, \ldots, x_{t-1})} = \exp(T \cdot \mathcal{L}).\]This is how “surprised” the model is by the data: a large value means the model assigned low probability to what actually happened. But this quantity grows exponentially with $T$, so it is useless for comparing datasets of different lengths. To normalize, take the $T$-th root — the geometric mean of the per-token inverse probabilities:
\[\text{perplexity} = \left(\frac{1}{\prod_{t=1}^{T} p_\theta(x_t \mid x_1, \ldots, x_{t-1})}\right)^{1/T} = \exp(\mathcal{L}).\]Equivalently, if $\bar{p}$ is the geometric mean probability the model assigns to each correct token, then perplexity $= 1/\bar{p}$.
Why call it “effective number of choices”? If the model assigned uniform probability $1/k$ to $k$ tokens at every step, the geometric mean probability would be $1/k$ and perplexity would be exactly $k$. So a perplexity of $3.5$ means the model is, on average, as uncertain as if it were choosing uniformly among $3.5$ options. A perplexity of $1$ means $\bar{p} = 1$: the model predicts every token with certainty. A perplexity of $65$ (our vocab size) means the model has learned nothing.
| Model | Loss (nats/token) | Perplexity |
|---|---|---|
| Uniform baseline | $4.17$ | $65.0$ |
| Last embedding (bigram) | $2.45$ | $11.6$ |
| 4-layer transformer | $1.25$ | $3.5$ |
| 8-layer transformer | $0.92$ | $2.5$ |
Perplexity is the standard metric in published language modeling results because it is comparable across different vocabulary sizes and sequence lengths in a way that raw loss is not.
9. Conclusion
We built a transformer from first principles: starting with raw embeddings, we added weighted combinations, softmax normalization, $\sqrt{d}$ scaling, learned query/key/value transformations, residual connections, and feed-forward layers. The resulting architecture — stacked transformer blocks trained with next-token prediction loss — is the foundation of modern language models.